# Reference: DSCI_571_sup-learn-1_students/lectures/code/plotting_functions.pyimport matplotlib.pyplot as pltimport mglearnfrom sklearn.tree import plot_tree# Custom function to customize the tree plot and hide values and samplesdef custom_plot_tree(tree_model, feature_names=None, class_names=None, **kwargs):""" Customizes and displays a tree plot for a scikit-learn Decision Tree Classifier. Parameters: - tree (sklearn.tree.DecisionTreeClassifier): The trained Decision Tree Classifier to visualize. - width: width of the matplotlib plot in inches - height: height of the matplotlib plot in inches - feature_names (list or None): A list of feature names to label the tree nodes with feature names. If None, generic feature names will be used. - class_names (list or None): A list of class names to label the tree nodes with class names. If None, generic class names will be used. - **kwargs: Additional keyword arguments to be passed to the `sklearn.tree.plot_tree` function. Returns: - None: The function displays the customized tree plot using Matplotlib. This function customizes the appearance of a Decision Tree plot generated by the scikit-learn `plot_tree` function. It hides both the samples and values in each node of the tree plot for improved visualization. """ plot_tree(tree_model, feature_names=feature_names, class_names=class_names, filled=True, **kwargs)# Customize the appearance of the text elements for each nodefor text in plt.gca().texts: new_text = re.sub('samples = \d+\n', '', text.get_text()) # Hide samples text.set_text(new_text) plt.show()def plot_tree_decision_boundary( model, X, y, x_label="x-axis", y_label="y-axis", eps=None, ax=None, title=None):if ax isNone: ax = plt.gca()if title isNone: title ="max_depth=%d"% (model.tree_.max_depth) mglearn.plots.plot_2d_separator( model, X.to_numpy(), eps=eps, fill=True, alpha=0.5, ax=ax ) mglearn.discrete_scatter(X.iloc[:, 0], X.iloc[:, 1], y, ax=ax) ax.set_xlabel(x_label) ax.set_ylabel(y_label) ax.set_title(title)def plot_tree_decision_boundary_and_tree( model, X, y, height=6, width=16, fontsize =9, x_label="x-axis", y_label="y-axis", eps=None): fig, ax = plt.subplots(1,2, figsize=(width, height), subplot_kw={"xticks": (), "yticks": ()}, gridspec_kw={"width_ratios": [1.5, 2]}, ) plot_tree_decision_boundary(model, X, y, x_label, y_label, eps, ax=ax[0]) custom_plot_tree(model, feature_names=X.columns.tolist(), class_names=['A+', 'not A+'], impurity=False, fontsize=fontsize, ax=ax[1]) ax[1].set_axis_off() plt.show()
Classification
read df
import pandas as pddf = pd.read_csv("data/quiz2-grade-toy-classification.csv")df.head()
ml_experience
class_attendance
lab1
lab2
lab3
lab4
quiz1
quiz2
0
1
1
92
93
84
91
92
A+
1
1
0
94
90
80
83
91
not A+
2
0
0
78
85
83
80
80
not A+
3
0
1
91
94
92
91
89
A+
4
0
1
77
83
90
92
85
A+
from sklearn.tree import DecisionTreeClassifiery, X = df.pop("quiz2"), dfclf = DecisionTreeClassifier()clf.fit(X, y)clf.predict(X)
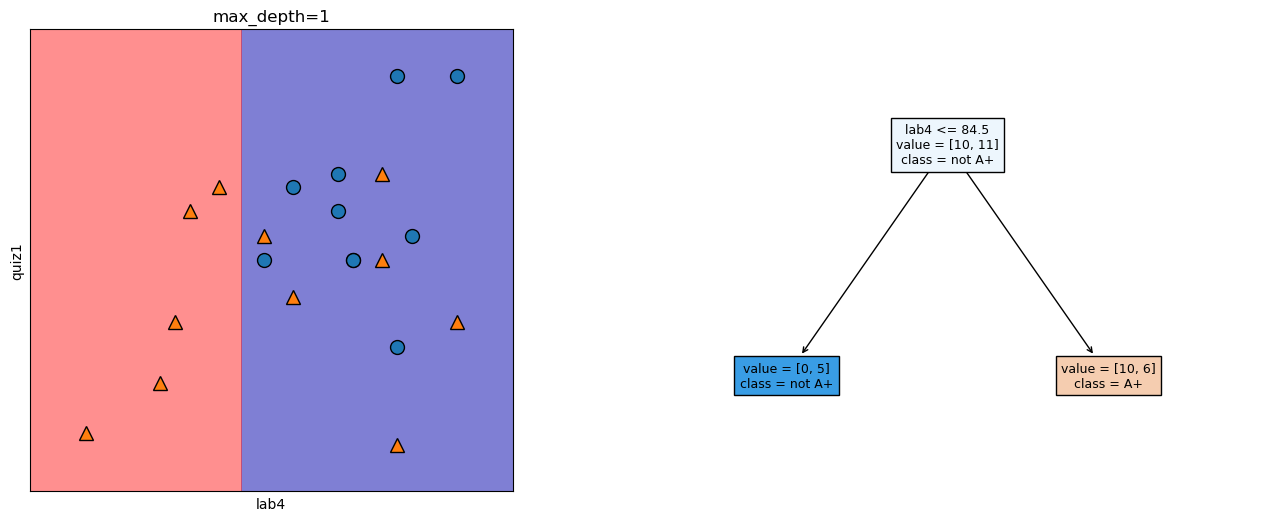
from sklearn.tree import DecisionTreeClassifierX = df[['lab4', 'quiz1']]clf = DecisionTreeClassifier(max_depth=1)clf.fit(X, y)clf.predict(X)plot_tree_decision_boundary_and_tree(clf, X, y, x_label='lab4', y_label='quiz1')
/Users/johnshiu/miniconda3/envs/571/lib/python3.11/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but DecisionTreeClassifier was fitted with feature names
warnings.warn(
Regression
read df
import pandas as pd# Prepare datadf = pd.read_csv("data/quiz2-grade-toy-regression.csv")df.head()
ml_experience
class_attendance
lab1
lab2
lab3
lab4
quiz1
quiz2
0
1
1
92
93
84
91
92
90
1
1
0
94
90
80
83
91
84
2
0
0
78
85
83
80
80
82
3
0
1
91
94
92
91
89
92
4
0
1
77
83
90
92
85
90
from sklearn.tree import DecisionTreeRegressory, X = df.pop("quiz2"), dfreg = DummyRegressor(strategy="mean")reg.fit(X, y)reg.predict(X)
If None, the decision tree could be creating very specific rules, based on just one example from the data
If max_depth = 1, the tree is called Decision stump
min_samples_split
min_samples_leaf
max_leaf_nodes
Pros
Cons
Remarks
?DecisionTreeClassifier
?DecisionTreeClassifier
Init signature:
DecisionTreeClassifier(*,
criterion='gini',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0,)Docstring:
A decision tree classifier.
Read more in the :ref:`User Guide <tree>`.
Parameters
----------
criterion : {"gini", "entropy", "log_loss"}, default="gini"
The function to measure the quality of a split. Supported criteria are
"gini" for the Gini impurity and "log_loss" and "entropy" both for the
Shannon information gain, see :ref:`tree_mathematical_formulation`.
splitter : {"best", "random"}, default="best"
The strategy used to choose the split at each node. Supported
strategies are "best" to choose the best split and "random" to choose
the best random split.
max_depth : int, default=None
The maximum depth of the tree. If None, then nodes are expanded until
all leaves are pure or until all leaves contain less than
min_samples_split samples.
min_samples_split : int or float, default=2
The minimum number of samples required to split an internal node:
- If int, then consider `min_samples_split` as the minimum number.
- If float, then `min_samples_split` is a fraction and
`ceil(min_samples_split * n_samples)` are the minimum
number of samples for each split.
.. versionchanged:: 0.18
Added float values for fractions.
min_samples_leaf : int or float, default=1
The minimum number of samples required to be at a leaf node.
A split point at any depth will only be considered if it leaves at
least ``min_samples_leaf`` training samples in each of the left and
right branches. This may have the effect of smoothing the model,
especially in regression.
- If int, then consider `min_samples_leaf` as the minimum number.
- If float, then `min_samples_leaf` is a fraction and
`ceil(min_samples_leaf * n_samples)` are the minimum
number of samples for each node.
.. versionchanged:: 0.18
Added float values for fractions.
min_weight_fraction_leaf : float, default=0.0
The minimum weighted fraction of the sum total of weights (of all
the input samples) required to be at a leaf node. Samples have
equal weight when sample_weight is not provided.
max_features : int, float or {"auto", "sqrt", "log2"}, default=None
The number of features to consider when looking for the best split:
- If int, then consider `max_features` features at each split.
- If float, then `max_features` is a fraction and
`max(1, int(max_features * n_features_in_))` features are considered at
each split.
- If "sqrt", then `max_features=sqrt(n_features)`.
- If "log2", then `max_features=log2(n_features)`.
- If None, then `max_features=n_features`.
Note: the search for a split does not stop until at least one
valid partition of the node samples is found, even if it requires to
effectively inspect more than ``max_features`` features.
random_state : int, RandomState instance or None, default=None
Controls the randomness of the estimator. The features are always
randomly permuted at each split, even if ``splitter`` is set to
``"best"``. When ``max_features < n_features``, the algorithm will
select ``max_features`` at random at each split before finding the best
split among them. But the best found split may vary across different
runs, even if ``max_features=n_features``. That is the case, if the
improvement of the criterion is identical for several splits and one
split has to be selected at random. To obtain a deterministic behaviour
during fitting, ``random_state`` has to be fixed to an integer.
See :term:`Glossary <random_state>` for details.
max_leaf_nodes : int, default=None
Grow a tree with ``max_leaf_nodes`` in best-first fashion.
Best nodes are defined as relative reduction in impurity.
If None then unlimited number of leaf nodes.
min_impurity_decrease : float, default=0.0
A node will be split if this split induces a decrease of the impurity
greater than or equal to this value.
The weighted impurity decrease equation is the following::
N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
where ``N`` is the total number of samples, ``N_t`` is the number of
samples at the current node, ``N_t_L`` is the number of samples in the
left child, and ``N_t_R`` is the number of samples in the right child.
``N``, ``N_t``, ``N_t_R`` and ``N_t_L`` all refer to the weighted sum,
if ``sample_weight`` is passed.
.. versionadded:: 0.19
class_weight : dict, list of dict or "balanced", default=None
Weights associated with classes in the form ``{class_label: weight}``.
If None, all classes are supposed to have weight one. For
multi-output problems, a list of dicts can be provided in the same
order as the columns of y.
Note that for multioutput (including multilabel) weights should be
defined for each class of every column in its own dict. For example,
for four-class multilabel classification weights should be
[{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] instead of
[{1:1}, {2:5}, {3:1}, {4:1}].
The "balanced" mode uses the values of y to automatically adjust
weights inversely proportional to class frequencies in the input data
as ``n_samples / (n_classes * np.bincount(y))``
For multi-output, the weights of each column of y will be multiplied.
Note that these weights will be multiplied with sample_weight (passed
through the fit method) if sample_weight is specified.
ccp_alpha : non-negative float, default=0.0
Complexity parameter used for Minimal Cost-Complexity Pruning. The
subtree with the largest cost complexity that is smaller than
``ccp_alpha`` will be chosen. By default, no pruning is performed. See
:ref:`minimal_cost_complexity_pruning` for details.
.. versionadded:: 0.22
Attributes
----------
classes_ : ndarray of shape (n_classes,) or list of ndarray
The classes labels (single output problem),
or a list of arrays of class labels (multi-output problem).
feature_importances_ : ndarray of shape (n_features,)
The impurity-based feature importances.
The higher, the more important the feature.
The importance of a feature is computed as the (normalized)
total reduction of the criterion brought by that feature. It is also
known as the Gini importance [4]_.
Warning: impurity-based feature importances can be misleading for
high cardinality features (many unique values). See
:func:`sklearn.inspection.permutation_importance` as an alternative.
max_features_ : int
The inferred value of max_features.
n_classes_ : int or list of int
The number of classes (for single output problems),
or a list containing the number of classes for each
output (for multi-output problems).
n_features_in_ : int
Number of features seen during :term:`fit`.
.. versionadded:: 0.24
feature_names_in_ : ndarray of shape (`n_features_in_`,)
Names of features seen during :term:`fit`. Defined only when `X`
has feature names that are all strings.
.. versionadded:: 1.0
n_outputs_ : int
The number of outputs when ``fit`` is performed.
tree_ : Tree instance
The underlying Tree object. Please refer to
``help(sklearn.tree._tree.Tree)`` for attributes of Tree object and
:ref:`sphx_glr_auto_examples_tree_plot_unveil_tree_structure.py`
for basic usage of these attributes.
See Also
--------
DecisionTreeRegressor : A decision tree regressor.
Notes
-----
The default values for the parameters controlling the size of the trees
(e.g. ``max_depth``, ``min_samples_leaf``, etc.) lead to fully grown and
unpruned trees which can potentially be very large on some data sets. To
reduce memory consumption, the complexity and size of the trees should be
controlled by setting those parameter values.
The :meth:`predict` method operates using the :func:`numpy.argmax`
function on the outputs of :meth:`predict_proba`. This means that in
case the highest predicted probabilities are tied, the classifier will
predict the tied class with the lowest index in :term:`classes_`.
References
----------
.. [1] https://en.wikipedia.org/wiki/Decision_tree_learning
.. [2] L. Breiman, J. Friedman, R. Olshen, and C. Stone, "Classification
and Regression Trees", Wadsworth, Belmont, CA, 1984.
.. [3] T. Hastie, R. Tibshirani and J. Friedman. "Elements of Statistical
Learning", Springer, 2009.
.. [4] L. Breiman, and A. Cutler, "Random Forests",
https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
Examples
--------
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.tree import DecisionTreeClassifier
>>> clf = DecisionTreeClassifier(random_state=0)
>>> iris = load_iris()
>>> cross_val_score(clf, iris.data, iris.target, cv=10)
... # doctest: +SKIP
...
array([ 1. , 0.93..., 0.86..., 0.93..., 0.93...,
0.93..., 0.93..., 1. , 0.93..., 1. ])
File: ~/miniconda3/envs/571/lib/python3.11/site-packages/sklearn/tree/_classes.py
Type: ABCMeta
Subclasses: ExtraTreeClassifier
?DecisionTreeRegressor
?DecisionTreeRegressor
Init signature:
DecisionTreeRegressor(*,
criterion='squared_error',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
ccp_alpha=0.0,)Docstring:
A decision tree regressor.
Read more in the :ref:`User Guide <tree>`.
Parameters
----------
criterion : {"squared_error", "friedman_mse", "absolute_error", "poisson"}, default="squared_error"
The function to measure the quality of a split. Supported criteria
are "squared_error" for the mean squared error, which is equal to
variance reduction as feature selection criterion and minimizes the L2
loss using the mean of each terminal node, "friedman_mse", which uses
mean squared error with Friedman's improvement score for potential
splits, "absolute_error" for the mean absolute error, which minimizes
the L1 loss using the median of each terminal node, and "poisson" which
uses reduction in Poisson deviance to find splits.
.. versionadded:: 0.18
Mean Absolute Error (MAE) criterion.
.. versionadded:: 0.24
Poisson deviance criterion.
splitter : {"best", "random"}, default="best"
The strategy used to choose the split at each node. Supported
strategies are "best" to choose the best split and "random" to choose
the best random split.
max_depth : int, default=None
The maximum depth of the tree. If None, then nodes are expanded until
all leaves are pure or until all leaves contain less than
min_samples_split samples.
min_samples_split : int or float, default=2
The minimum number of samples required to split an internal node:
- If int, then consider `min_samples_split` as the minimum number.
- If float, then `min_samples_split` is a fraction and
`ceil(min_samples_split * n_samples)` are the minimum
number of samples for each split.
.. versionchanged:: 0.18
Added float values for fractions.
min_samples_leaf : int or float, default=1
The minimum number of samples required to be at a leaf node.
A split point at any depth will only be considered if it leaves at
least ``min_samples_leaf`` training samples in each of the left and
right branches. This may have the effect of smoothing the model,
especially in regression.
- If int, then consider `min_samples_leaf` as the minimum number.
- If float, then `min_samples_leaf` is a fraction and
`ceil(min_samples_leaf * n_samples)` are the minimum
number of samples for each node.
.. versionchanged:: 0.18
Added float values for fractions.
min_weight_fraction_leaf : float, default=0.0
The minimum weighted fraction of the sum total of weights (of all
the input samples) required to be at a leaf node. Samples have
equal weight when sample_weight is not provided.
max_features : int, float or {"auto", "sqrt", "log2"}, default=None
The number of features to consider when looking for the best split:
- If int, then consider `max_features` features at each split.
- If float, then `max_features` is a fraction and
`max(1, int(max_features * n_features_in_))` features are considered at each
split.
- If "sqrt", then `max_features=sqrt(n_features)`.
- If "log2", then `max_features=log2(n_features)`.
- If None, then `max_features=n_features`.
Note: the search for a split does not stop until at least one
valid partition of the node samples is found, even if it requires to
effectively inspect more than ``max_features`` features.
random_state : int, RandomState instance or None, default=None
Controls the randomness of the estimator. The features are always
randomly permuted at each split, even if ``splitter`` is set to
``"best"``. When ``max_features < n_features``, the algorithm will
select ``max_features`` at random at each split before finding the best
split among them. But the best found split may vary across different
runs, even if ``max_features=n_features``. That is the case, if the
improvement of the criterion is identical for several splits and one
split has to be selected at random. To obtain a deterministic behaviour
during fitting, ``random_state`` has to be fixed to an integer.
See :term:`Glossary <random_state>` for details.
max_leaf_nodes : int, default=None
Grow a tree with ``max_leaf_nodes`` in best-first fashion.
Best nodes are defined as relative reduction in impurity.
If None then unlimited number of leaf nodes.
min_impurity_decrease : float, default=0.0
A node will be split if this split induces a decrease of the impurity
greater than or equal to this value.
The weighted impurity decrease equation is the following::
N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
where ``N`` is the total number of samples, ``N_t`` is the number of
samples at the current node, ``N_t_L`` is the number of samples in the
left child, and ``N_t_R`` is the number of samples in the right child.
``N``, ``N_t``, ``N_t_R`` and ``N_t_L`` all refer to the weighted sum,
if ``sample_weight`` is passed.
.. versionadded:: 0.19
ccp_alpha : non-negative float, default=0.0
Complexity parameter used for Minimal Cost-Complexity Pruning. The
subtree with the largest cost complexity that is smaller than
``ccp_alpha`` will be chosen. By default, no pruning is performed. See
:ref:`minimal_cost_complexity_pruning` for details.
.. versionadded:: 0.22
Attributes
----------
feature_importances_ : ndarray of shape (n_features,)
The feature importances.
The higher, the more important the feature.
The importance of a feature is computed as the
(normalized) total reduction of the criterion brought
by that feature. It is also known as the Gini importance [4]_.
Warning: impurity-based feature importances can be misleading for
high cardinality features (many unique values). See
:func:`sklearn.inspection.permutation_importance` as an alternative.
max_features_ : int
The inferred value of max_features.
n_features_in_ : int
Number of features seen during :term:`fit`.
.. versionadded:: 0.24
feature_names_in_ : ndarray of shape (`n_features_in_`,)
Names of features seen during :term:`fit`. Defined only when `X`
has feature names that are all strings.
.. versionadded:: 1.0
n_outputs_ : int
The number of outputs when ``fit`` is performed.
tree_ : Tree instance
The underlying Tree object. Please refer to
``help(sklearn.tree._tree.Tree)`` for attributes of Tree object and
:ref:`sphx_glr_auto_examples_tree_plot_unveil_tree_structure.py`
for basic usage of these attributes.
See Also
--------
DecisionTreeClassifier : A decision tree classifier.
Notes
-----
The default values for the parameters controlling the size of the trees
(e.g. ``max_depth``, ``min_samples_leaf``, etc.) lead to fully grown and
unpruned trees which can potentially be very large on some data sets. To
reduce memory consumption, the complexity and size of the trees should be
controlled by setting those parameter values.
References
----------
.. [1] https://en.wikipedia.org/wiki/Decision_tree_learning
.. [2] L. Breiman, J. Friedman, R. Olshen, and C. Stone, "Classification
and Regression Trees", Wadsworth, Belmont, CA, 1984.
.. [3] T. Hastie, R. Tibshirani and J. Friedman. "Elements of Statistical
Learning", Springer, 2009.
.. [4] L. Breiman, and A. Cutler, "Random Forests",
https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
Examples
--------
>>> from sklearn.datasets import load_diabetes
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.tree import DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y=True)
>>> regressor = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressor, X, y, cv=10)
... # doctest: +SKIP
...
array([-0.39..., -0.46..., 0.02..., 0.06..., -0.50...,
0.16..., 0.11..., -0.73..., -0.30..., -0.00...])
File: ~/miniconda3/envs/571/lib/python3.11/site-packages/sklearn/tree/_classes.py
Type: ABCMeta
Subclasses: ExtraTreeRegressor